
Optimising and Scaling your Confluent Cluster
Author: Oscar Moores
Release Date: 04/08/2025

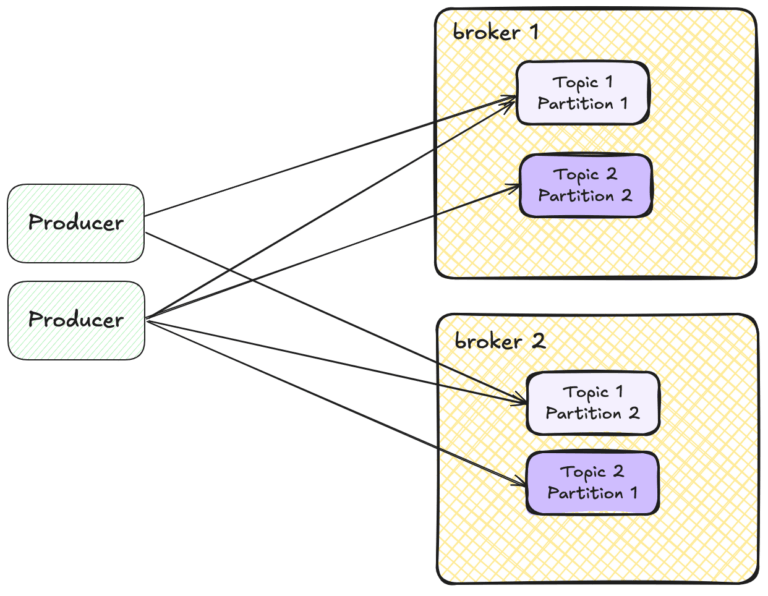
Easier to scale than consumers, you can just spin up a new producer and point it at the topic you want data sent to but this is not always necessary as with careful configuration it may be possible to increase a producer's throughput rather than starting up a new one.
A producer can cause a bottleneck in a number of ways: The producers CPU could be at capacity, maybe it doesn’t have enough memory or it's limited by how fast it can read from a hard drive. When this occurs it may be necessary to start more producers, but equally optimising the code of the producer or improving the hardware isn’t always impossible.
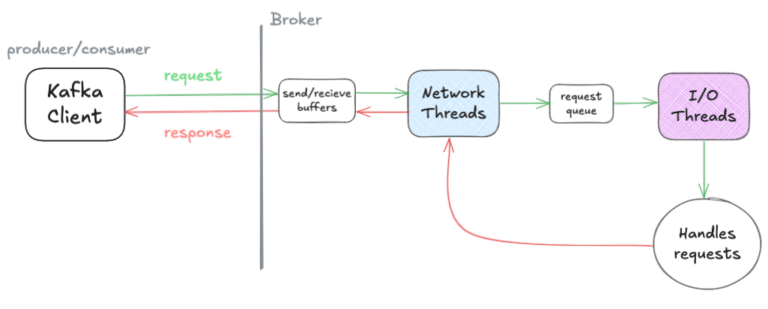
The load on the threads can be monitored using metrics.
If the metric ‘NetworkProcessorAvgIdlePercent’ is low it is an indicator that the load on a broker's network threads is high, and could be a bottleneck for performance. To enable more network threads increase the value of the ‘num.network.threads’ setting.
I/O threads do not have a metric that can directly be used to monitor them, instead a pair can be used to get an idea of how well they are coping: ‘RequestQueueSize’ and ‘RequestQueueTimeMs’. These metrics monitor the queue of requests that the I/O thread takes from, its size and how long requests have been in it. If these metrics are high it probably means the I/O threads are struggling as it is taking a long time for requests to be handled. To increase the number of I/O threads increase ‘num.io.threads’ on the broker.
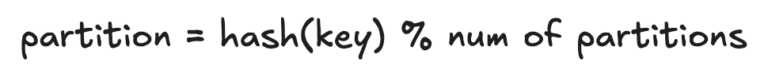
The easiest way to deal with this problem is to anticipate how many consumers you will need and make sure you have at least this many partitions when you create the topic, but an unforeseen increase in demand could mean you need to add more partitions after creation.
If you have to add more partitions to an already existing topic and need data with the same key to always be in the same partition one possible solution is creating a new topic with the desired number of partitions and using a tool like ksql or Kafka streams to read the data from the current topic and produce it to the new topic. Reconsuming the data like this means all records will be partitioned again, putting each key into the same partition.
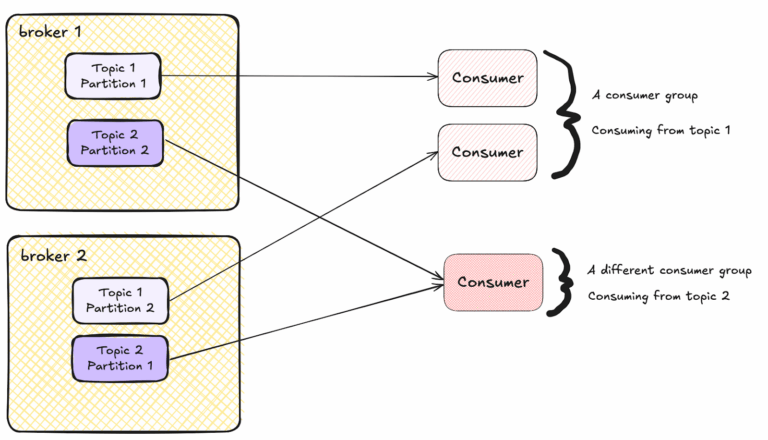
If you need to scale your data output from Confluent one of the first things to check is the load on your consumers, monitoring the cpu, memory and any storage. If these are at capacity then more consumers may need to be added to share the load, the hardware upgraded, the consumer code/settings optimised or more consumers added.