
How to Build a Data Pipeline with Confluent
Author: Sam Ward
Release Date: 29/09/2025
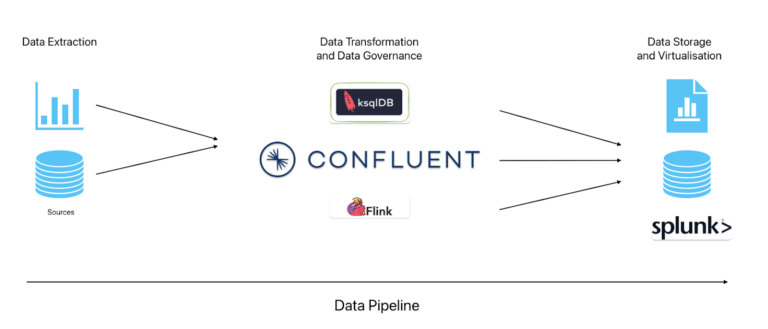
Stages of a Data Pipeline
Data Extraction: This is the phase where we collect data from various sources, from tables in a database, to IoT devices. In a typical data pipeline, these sources can either be streams of data (such as a real-time live collection of data every second from an IoT device) or batches of data (such as a static table). With Confluent, we use continuous streams of data so we’ll focus on this type of data pipeline in this blog post.
Data Transformation: This is where we process data and perform a wide range of different tasks upon the data. This includes: extracting data from stream and processing it into a specified format, enriching a stream of data with additional metadata and filtering out specific events based on values detected. Flink and ksqlDB are examples of stream processing frameworks/engines that allow developers to have fine control over the data their system processes. This stage does not necessarily involve full data transformation, for example a specific pipeline could simply reformat data ready for storage/virtualisation.
In this stage, we also consider Data Governance but with Confluent this is built-in with the use of topics, stream lineage, schema validation and schema linking. For more information on what Data Governance is within Confluent, see the following article written by Confluent themselves.
Data Storage: Once our data has been processed and we have defined our data types and conditions, we can store our data in a system such as Amazon S3, MongoDB or any JDBC compatible database with Confluent’s sink connectors. This is often for further analysis of data (another , but this can also be output simply for use by endpoint applications.
In Practice: What Does a Pipeline Look Like?
Let’s dive into what one of these pipelines looks like in a practice environment, and what components we’ll need to set up a very basic data pipeline:
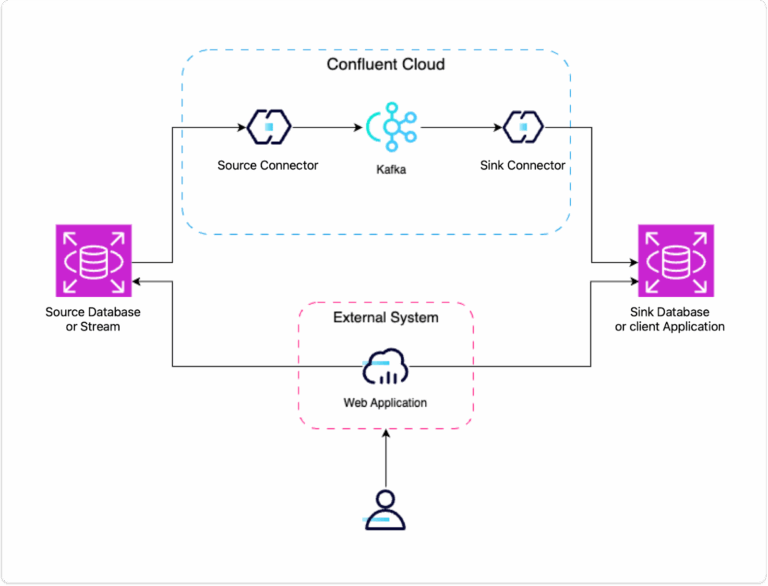
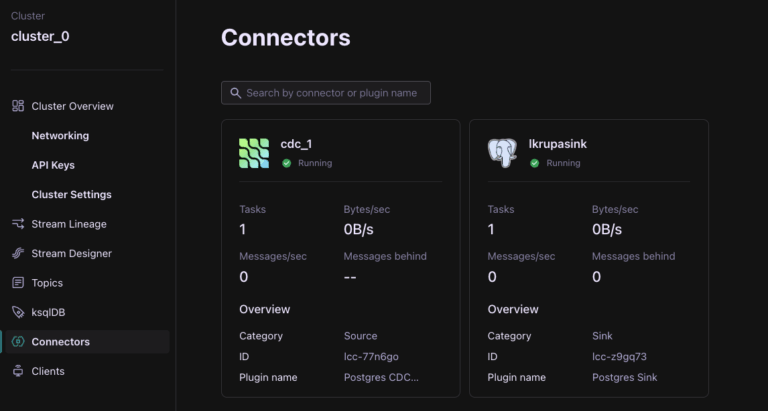
As you can see from the image above, we’ve got two connectors in Confluent Cloud running, one source (PostgreSQL CDC Source Connector) and one sink (PostgreSQL Sink Connector). To see how to set these up and get some hands-on experience yourself, you can join one of our Confluent 101 Workshops, hosted by me!
If you’re curious about what source and sink connectors are available with Confluent Cloud, see the list here.