
5 Issues Splunk Observability Cloud Solves
Author: Owais Ghaffar
Release Date: 15/10/2025

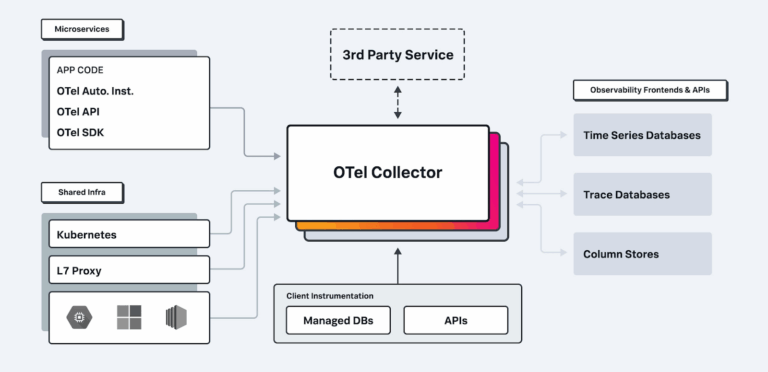
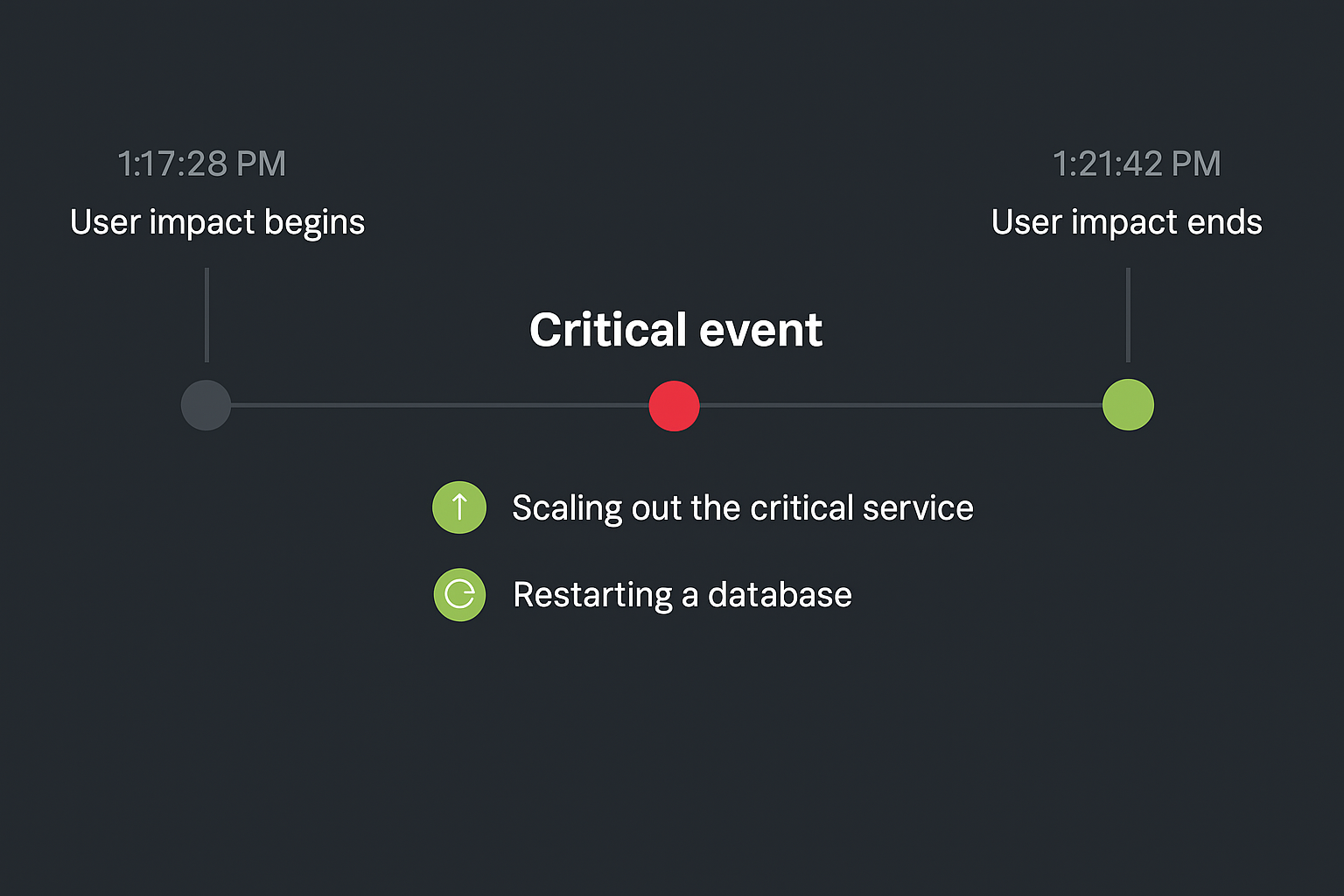
2. High MTTR (Mean Time To Resolution)
The Problem: When something breaks, multiple teams get involved—AppDev, Infra, SecOps. Hours are wasted piecing together logs, metrics, and alerts from different tools.
How Splunk Helps:
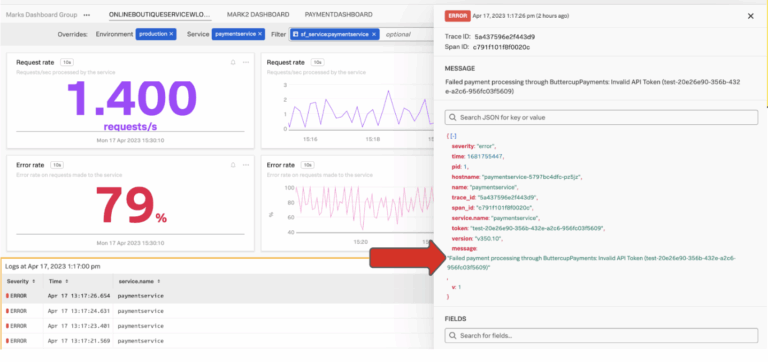
3. Inability to Monitor SLAs and SLOs Effectively
The Problem: Businesses commit to performance standards (SLAs and SLOs), but most teams can’t see these metrics in real time or tie them to user experience.
How Splunk Helps:
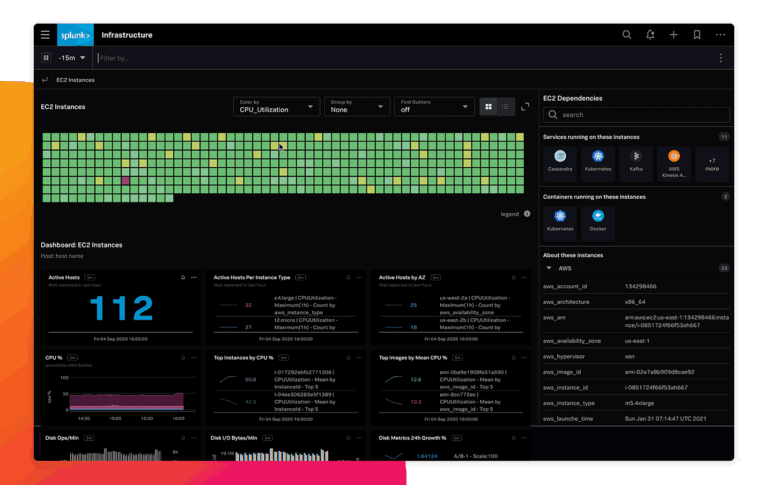
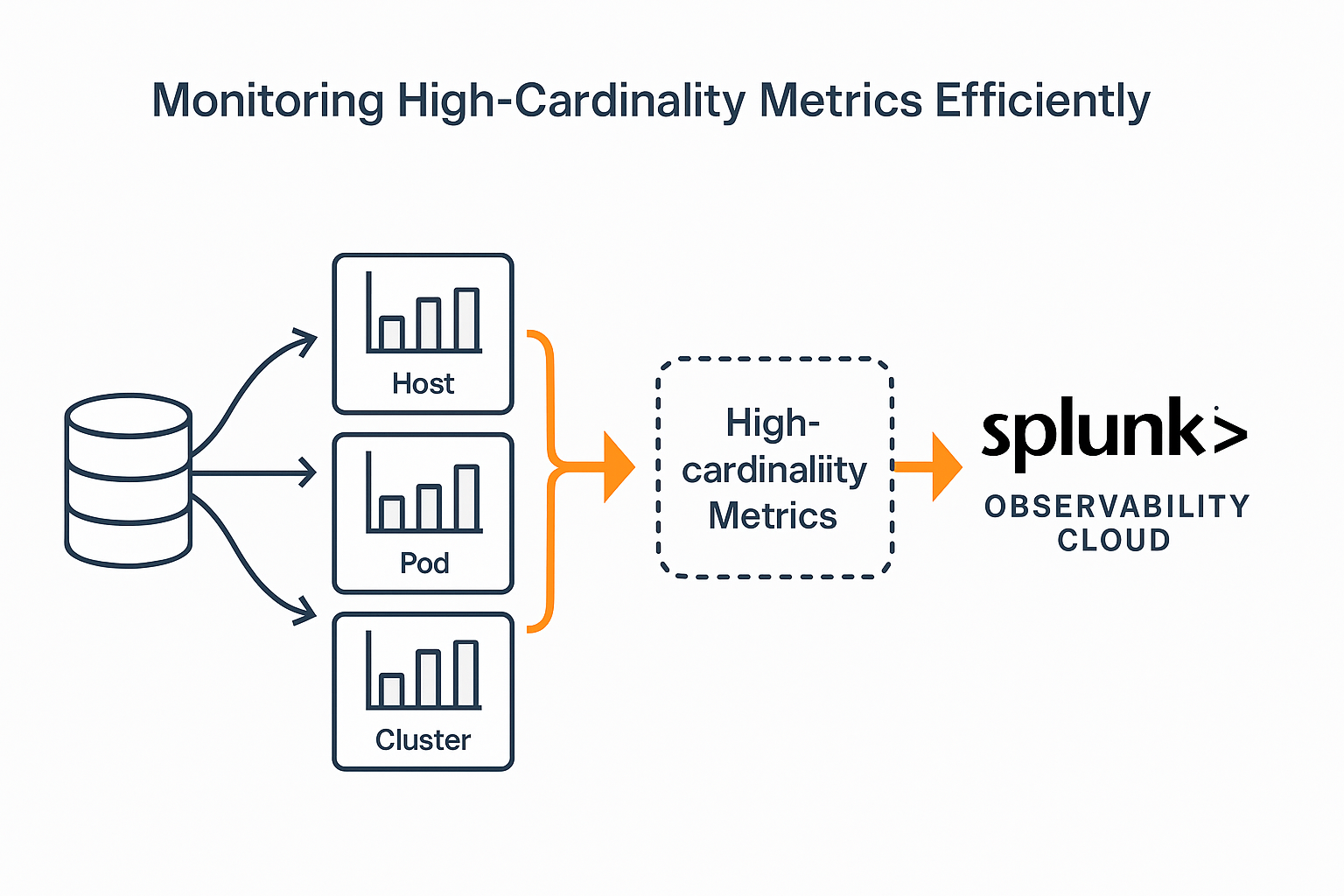
4. Scaling Observability Without Breaking the Budget
The Problem: Some observability tools charge based on cardinality (number of unique metric combinations), or by ingest volume—costs quickly balloon.
How Splunk Helps:
5. Lack of End-to-End Visibility in Regulated Industries
The Problem: Organisations in finance, insurance, and government face strict compliance requirements. Auditing outages or latency spikes can be painful without traceability.
How Splunk Helps:
Final Thoughts
Modern observability isn’t just about seeing everything—it’s about understanding everything in context. Splunk Observability Cloud helps medium to large organisations tame complexity, reduce downtime, and align technical performance with business success.
It goes beyond observability—it empowers your teams to act faster and smarter.