
Grafana Cloud: Observability and Visualisation Made Easy (4 Pillars of Observability Part #1)
Author: Oscar Moores
Release Date: 20/01/2026

The Grafana stack - a set of tools for end to end collecting, storing and analysing metrics, logs, traces and profiles in a cost effective and scalable way:

Getting Data into Grafana with Alloy
Previously I stated Grafana wasn’t just about using data you already have and that you could collect data leaving open the question: “How exactly do I get data into Grafana?”. The answer to this question (pretend you haven’t seen the title of the section) is Grafana Alloy.
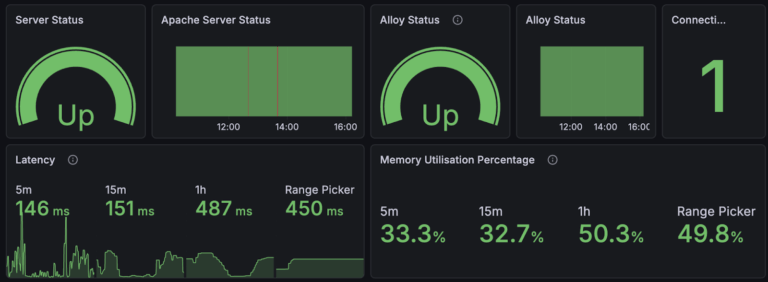
Grafana Alloy is an OpenTelemetry compatible agent that can be deployed to collect metrics, logs, traces and profiles. When you install an agent you can configure it locally, it is able to scrape from files and endpoints to gather whatever it needs and then send everything to their appropriate backend be that Prometheus, Loki or any of Grafana's other storage solutions. Processing is also possible in Alloy, you can reformat or transform values and labels to clean or organise data to get as much value in Grafana with minimal effort.
Another useful feature that is worth mentioning in relation to Grafana Alloy is fleet management, which is a centralised way to monitor each instance of Alloy as well as apply configuration based on the characteristics of whatever each Alloy instance is being run on. Troubleshooting is made much easier by this as you can view the metrics and logs of an Alloy instance in one location and don’t have to configure each instance to send their own logs and metrics to Grafana.
Alloy is a reliable and versatile tool for collecting telemetry and whenever trying to get metrics, logs, traces and profiles to send to their appropriate backends, Grafana Alloy is most likely what you will use, with additional features like clustering to increase availability and a built in UI for troubleshooting.
Link to Alloy documentation with references for how to use Alloy for the full Grafana stack: https://grafana.com/docs/alloy/latest/